
一、前言
日前,我接触学习了Nagios,在看到网上各路神仙写的杂七杂八的Nagios安装配置教程,亲自尝试许多的教程过后,“骂骂咧咧”的写下这篇关于Nagios的安装与配置较为完整且详细的博文(整合众多Nagios教程)。这是我第一次写博文,文中的语言表达和具体步骤或有欠缺和遗漏(如有错误,评论指出)。写博文不仅是记录自己学习的过程和总结,也是为了方便像我一样的小白,能够更快速的入门Nagios。本文中的内容是关于Nagios的一些介绍和基础的配置,基本能够帮助各位快速入门和使用Nagios。关于Nagios的一些罗里吧嗦的简介,基本都是参考别人的,只为了更好的帮助大家对Nagios的快速理解,或者只是为了本文的完整性罢了,最重要的是能学习到本文中具体的配置过程和思路,能对Nagios有一个清晰的认识,可以顺利完成Nagios安装和配置。在参考本文的Nagios安装和配置过程中,请尽量不要遗漏或错误执行我写的实验步骤,并且尽可能正确理解每行每句的意思。
二、Nagios简介
Nagios又被称为难够死,因为很难。Nagios是一款开源的网络及服务的监控工具,其功能强大、灵活性强。能有效监控windows、Linux和Unix等系统的主机各种状态信息,交换机、路由器等网络设备,以及主机端口及URL服务等。根据不同业务故障级别发出告警信息(邮件、微信、短信、语音报警、飞信、MSN)给管理员,当故障恢复时也会发出恢复消息给管理员。Nagios服务端可以在Unix及类Unix系统上运行,目前无法运行在windows。Windows可以作为被监控的主机,但是无法作为监控服务器。
三 、Nagios构成
Nagios不好的地方在于它只做核心,很多其他功能都是通过插件来实现的。Nagios一般由一个主程序(Nagios),一个插件程序(Nagios-plugins)和一些可选的附加程序(NRPE,NSClient++,NSCA,NDOUtils)等。Nagios本身就是一个监控的平台而已,其具体的监控工作都是通过插件(Nagios-plugins,也可自己编写)来实现的。因安装于被监控端。几个附加程序的描述如下:
1.NRPE:半被动模式
(1) 存在位置:工作在被监控端,操作系统为Linux/Unix;
(2) 作用:用于在被监控的远程Linux/Unix主机上执行脚本插件获取数据回传给服务器端,以实现对这些主机资源的监控。主要用于监控本地资源;
(3) 存在形式:守护进程(agent)模式,开启的端口为5666.
2.NSClient++:半被动模式
(1) 存在位置:监控Windows主机;
(2) 作用:相当于Linux下的NRPE;
3.**NDOUtils:不推荐使用 **
(1) 存在位置:Nagios服务器端;
(2)作用:用于将Nagios的配置信息和各event产生的数据存入数据库以实现对这些数据的检索和处理。但是存入数据库还不如存放在磁盘上,因此不推荐使用;
4.NSCA:纯被动模式的监控
(1)存在位置:同时安装在Nagios的服务器端和客户端;
(2) 作用:用于让被监控的远程Linux/Unix主机主动将监控到的信息发送给Nagios服务器。在分布式监控集群模式中要用到,300台服务器以内可以不考虑;
四 、Nagios原理
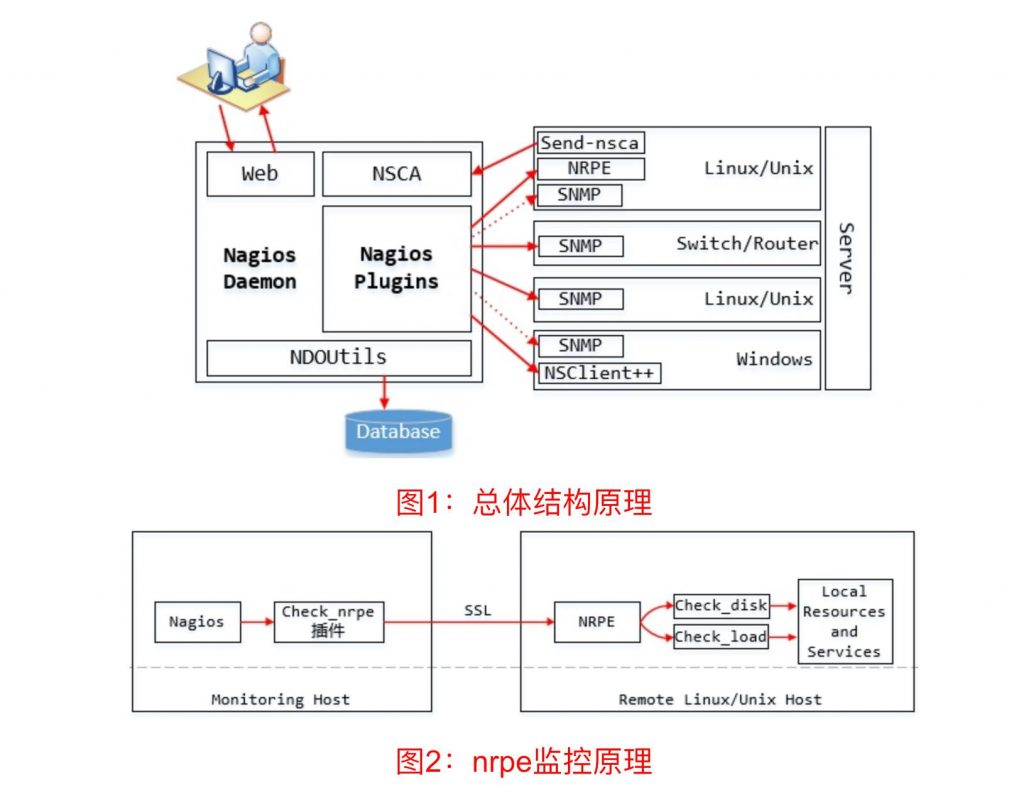
五 、安装介绍
1.说明
本次演示过程只涉及到两台虚拟机,具体是一台Nagios服务端监控一台Linux客户端。完成本实验的前提是Nagios服务端需要有LAMP的坏境,因为Nagios服务端的web界面需要Apache、PHP的支持。这里只要求有LAMP坏境就行,关于LAMP的坏境搭建部署,请参考这个教程 LAMP快速搭建。
2.主机介绍
| IP地址 | 主机 | 软件 |
|---|---|---|
| 192.168.5.245 | Nagios服务端 | Apache、Php、Nagios、nagios-plugins、nrpe |
| 192.168.5.246 | client被监控端(客户端) | nagios-plugins、nrpe |
(1)Server 安装了nagios软件,对监控的数据做处理,并且提供web界面查看和管理。
(2)Client 安装了NRPE等客户端,根据监控机的请求执行监控,然后将结果回传给监控机。哪台Linux想要被监控哪台Linux就装NRPE并运行NRPE插件。
(3)本次实验只是实现Nagios服务端远程监控linux客户端的磁盘占用率和系统负载等情况。
3.主要插件介绍
(1)NRPE
当Nagios服务端需要监控某个远程Linux 客户端的服务或者资源情况时:
1.Nagios服务端会运行check_nrpe 这个插件,告诉它要检查什么;
2.check_nrpe 插件会连接到远程客户端上的NRPE daemon,所用的方式是SSL;
3.NRPE daemon 会运行相应的Nagios 插件来执行检查;
4.NRPE daemon 将检查的结果返回给check_nrpe 插件,插件将其递交给nagios做处理
注意:NRPE daemon 需要Nagios 插件安装在远程的Linux主机上,否则,daemon不能做任何的监控。
(2)Nagios-plugins
nagios core是没有内置任何检查机制进行主机服务或者网络的监控。对于这些工作,都是交给额外的程序,就是nagios plugins程序来完成。Nagios只是一个平台,本身啥都不是,需要通过各种小弟(nagios plugins)才能干活。
六、 Nagios服务端安装
1.安装前准备:
(1)关闭防火墙:
[root@nagios-server ~]# systemctl stop firewalld.service #停止firewall [root@nagios-server ~]# systemctl disable firewalld.service #禁止firewall的开机自启动 [root@nagios-server ~]# iptables -F
关闭selinux:
[root@nagios-server ~]# setenforce 0 [root@nagios-server ~]# sed -ri 's#^(SELINUX=).*#\1disabled#g' /etc/selinux/config
(2)这里建议换掉yum源,使用阿里云的yum源,方便后续安装软件。更换yum源教程
(3)调整字符集,如果不安装后面安装一些插件会有错误:
[root@nagios-server ~]# echo 'export LC_ALL=C' >>/etc/profile [root@nagios-server ~]# source /etc/profile
(4)时间同步,监控的时间同步很重要:
[root@nagios-server ~]# echo '# time sync' >>/var/spool/cron/root [root@nagios-server ~]# echo '*/10 * * * * /usr/sbin/ntpdate pool.ntp.org &>/dev/null' >>/var/spool/cron/root
(5)Nagios服务端需要安装web展示依赖软件:
[root@nagios-server ~]#yum install -y gcc glibc glibc-common gd gd-devel httpd php php-gd mysql*
说明:这里可以看到yum 一键安装这些软件,不仅包含了编译器,图画等软件还包含了LAMP坏境。有些人的Centos7本身可能就搭建过了LAMP坏境,再执行这句yum安装命令也不会有事,不会重复安装LAMP,可能会升级安装过的LAMP。
安装的软件说明:
gcc glibc glibc-common gcc 编译器
gd gd-devel Nagios服务端Web界面中的Map画拓扑图用的
httpd php \php-gd php环境,LAMP坏境
mysql* 生成MySQL的插件,MySQL不需要启动
(6)创建所需用户,并将apache和nagios同属于一个组,方便一起管理:
[root@nagios-server ~]# useradd -m nagios [root@nagios-server ~]# groupadd nagcmd [root@nagios-server ~]# usermod -a -G nagcmd nagios [root@nagios-server ~]# usermod -a -G nagcmd apache
2.安装Nagios平台
(1)下载Nagios
[root@nagios-server ~]#cd /usr/local/src [root@nagios-server src]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.3.1.tar.gz
(2)解压编译安装
[root@nagios-server src]# tar -zxf nagios-4.3.1.tar.gz [root@nagios-server src]# ls nagios-4.3.1 nagios-4.3.1.tar.gz [root@nagios-server src]# cd nagios-4.3.1/ [root@nagios-server nagios-4.3.1]# ./configure --with-command-group=nagcmd [root@nagios-server nagios-4.3.1]#make all
说明:如果执行了make all后发现跟下图一样的报错,请执行yum -y install unzip zip方可解决。
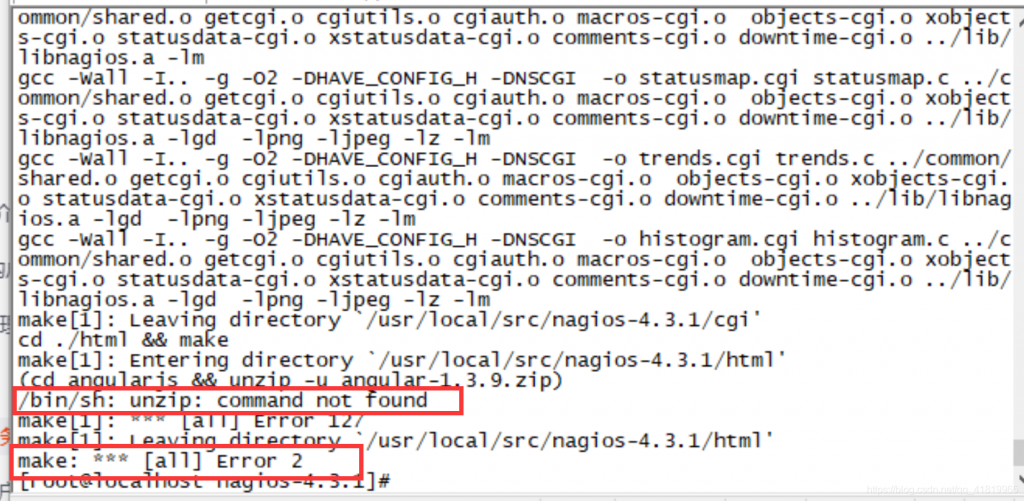
[root@nagios-server nagios-4.3.1]#make install [root@nagios-server nagios-4.3.1]#make install-init [root@nagios-server nagios-4.3.1]#make install-commandmode [root@nagios-server nagios-4.3.1]#make install-config [root@nagios-server nagios-4.3.1]#make install-webconf
要确保以上命令执行无错误。
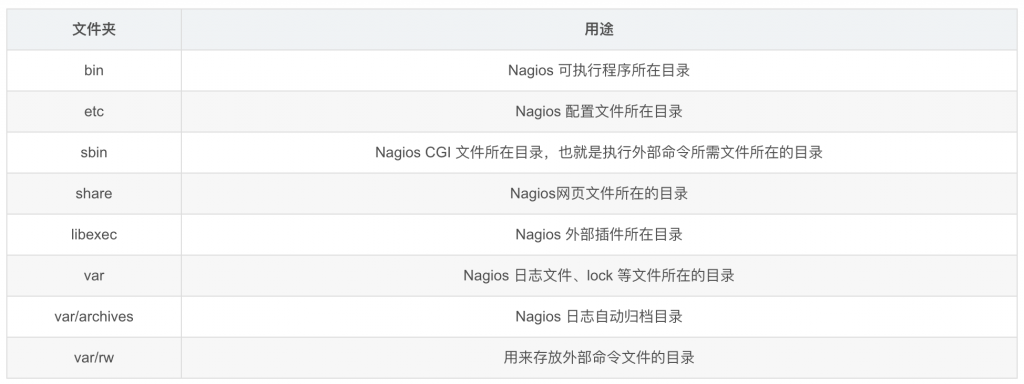
(3)Nagios目录说明
完成以上步骤之后,在/usr/local/nagios/ 目录下会生成一系列文件和文件夹,了解目录下的文件的用途对学习Nagios和排错有很大的帮助,下面进行解释说明每个文件夹的作用:
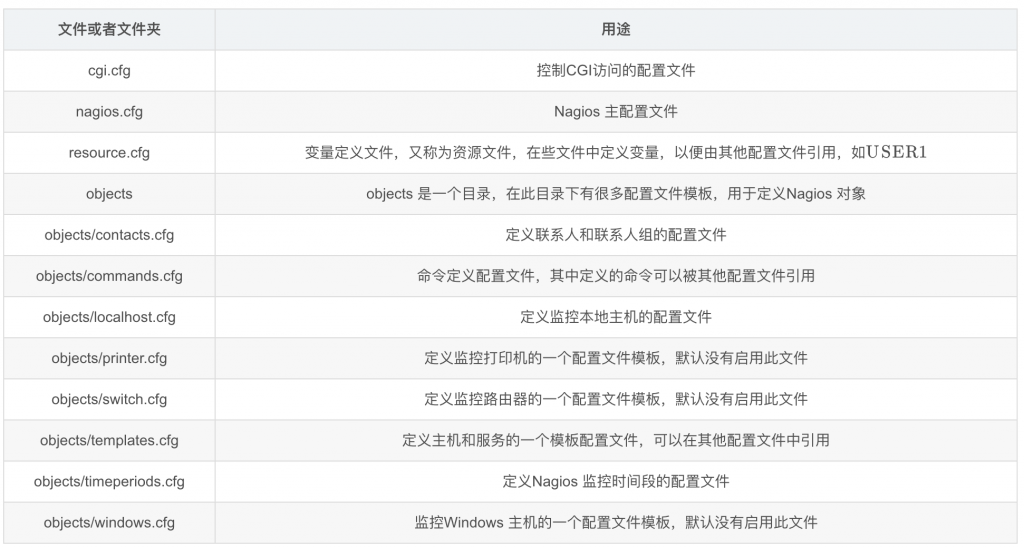
 Nagios 安装完毕后,默认的配置文件在/usr/local/nagios/etc目录下,文件用途解释说明:
Nagios 安装完毕后,默认的配置文件在/usr/local/nagios/etc目录下,文件用途解释说明:
(4)配置登录Nagios服务端Web界面的用户账号:wang 密码:123456
[root@nagios-server nagios-4.3.1]#htpasswd -cb /usr/local/nagios/etc/htpasswd.users wang 123456

(5)因为nagios默认把全部的权限给nagiosadmin,所以可以通过修改cgi.cfg文件授权给刚刚新建的wang这个用户。如果不授权给wang,后面完成Nagios配置之后,使用账号wang来登录Nagios服务端的Web界面,将会看不到你配置好的需要监控的主机的所有信息。
[root@nagios-server nagios-4.3.1]#cd /usr/local/nagios/etc [root@nagios-server etc]# ls cgi.cfg htpasswd.users nagios.cfg objects resource.cfg [root@nagios-server etc]# sed -i 's/nagiosadmin/nagiosadmin,wang/g' cgi.cfg [root@nagios-server etc]# grep nagiosadmin cgi.cfg authorized_for_system_information=nagiosadmin,wang authorized_for_configuration_information=nagiosadmin,wang authorized_for_system_commands=nagiosadmin,wang authorized_for_all_services=nagiosadmin,wang authorized_for_all_hosts=nagiosadmin,wang authorized_for_all_service_commands=nagiosadmin,wang authorized_for_all_host_commands=nagiosadmin,wang
从上面执行的grep nagiosadmin cgi.cfg查询语句反馈的结果可以看到cgi.cfg文件内的已经授权给用户wang。
(6)登录Nagios服务端的Web界面
重启apache、nagios
[root@nagios-server etc]# systemctl restart httpd [root@nagios-server etc]# systemctl start nagios
打开浏览器,输入地址:Nagios服务端主机的ip/nagios,输入用户wang密码123456,然后回车,结果如下图:
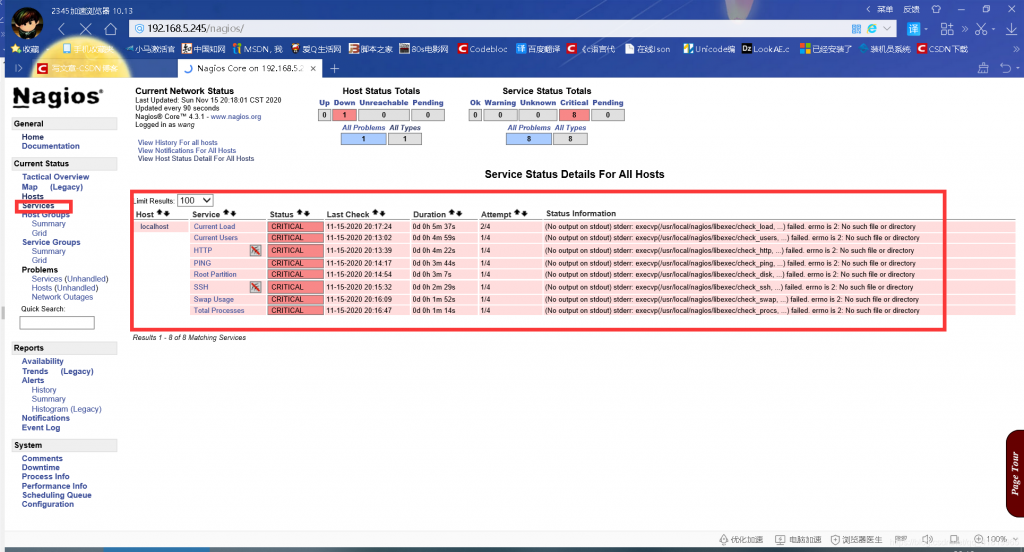
说明:从上图可以看到,监控localhost本机的一些服务全都是CRITICAL(危急),这是因为Nagios服务端默认启动/usr/local/nagios/etc/objects/localhost.cfg,这个文件是监控本机的配置文件,前面说了Nagios只是一个平台,是通过调用插件来干活的,执行下面这条命令,可以看见插件空空如也,所以还不能实现监控本机,下面将介绍安装插件步骤和过程(本实验也没想监控本机,后面会说到相关内容)。
[root@nagios-server etc]#ls /usr/local/nagios/libexec

3.安装Nagios-plugins插件
(1)安装前准备
安装依赖软件perl-devel
[root@nagios-server etc]#yum install -y perl-devel
(2)下载Nagios-plugins
[root@nagios-server etc]# cd /usr/local/src/
第一种方法:这里我提供了蓝奏云下载Nagios-plugins。
下载在本地电脑之后,用SecureCRT链接工具链接Nagios服务端,然后执行yum -y install lrzsz ,再然后执行rz命令上传刚才下载在本地电脑的Nagios-plugins插件压缩包,如下图。第二种方法:你也可以自己寻找下载链接,然后通过wget下载到Linux。
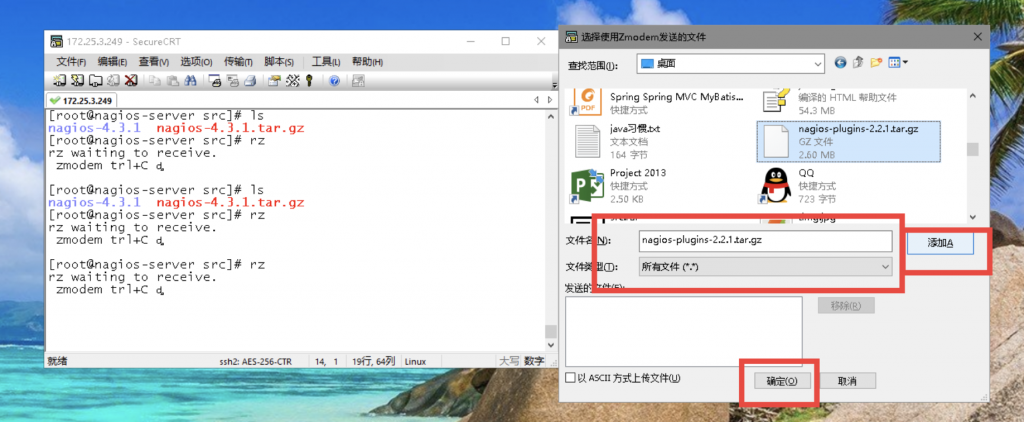
[root@nagios-server src]# yum -y install lrzsz [root@nagios-server src]# rz [root@nagios-server src]# ls nagios-4.3.1 nagios-4.3.1.tar.gz nagios-plugins-2.2.1.tar.gz
(3)解压编译安装
[root@nagios-server src]# tar -zxf nagios-plugins-2.2.1.tar.gz [root@nagios-server src]# cd nagios-plugins-2.2.1/ [root@nagios-server nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios --enable-perl-modules [root@nagios-server nagios-plugins-2.2.1]# make && make install [root@nagios-server nagios-plugins-2.2.1]# ls /usr/local/nagios/libexec/|wc -l 55
说明:这里安装了nagios-plugins后,可以查看/usr/local/nagios/libexec/目录下生成插件的个数,我这里是55个,越多越好,说明可监控的东西更多,生成插件的个数由当前所在Linux主机拥有的服务所决定。
4.安装NRPE插件
说明:刚才上面说了,哪台Linux想要被监控哪台Linux就装NRPE,可是我不需要监控本机啊!况且我只要Nagios服务端装好Nagios和nagios-plugins之后,启动apache和nagios服务,就会默认启动/usr/local/nagios/etc/objects/localhost.cfg这个配置文件,实现监控本机。那为什么还要在Nagios服务端装NRPE呢?
原因:Nagios服务端需要check_nrpe这个插件,才能实现与客户端的NRPE插件联系,它们之间是通过SSL协议通信。如果Nagios服务端不安装NRPE插件,在/usr/local/nagios/libexec/这个路径下,将找不到check_nrpe这个插件。所以Nagios 服务端需要装NRPE插件。Nagios服务端的NRPE不一定需要运行,但被监控的客户端的NRPE一定得运行起来。
NRPE总共由两部分组成: check_nrpe ----> 插件,位于监控主机上 NRPE daemon ----> 运行在远程的Linux客户端上(通常就是被监控机)
(1)NRPE下载
[root@nagios-server~]# cd /usr/local/src/ [root@nagios-server src]# wget http://prdownloads.sourceforge.net/sourceforge/nagios/nrpe-2.13.tar.gz
(2)NRPE解压编译安装
[root@nagios-server src]# tar zxf nrpe-2.13.tar.gz [root@nagios-server src]#cd nrpe-2.13 [root@nagios-server nrpe-2.13]# yum install -y openssl-devel
yum install -y openssl-devel ##这个是安装NRPE依赖
[root@nagios-server nrpe-2.13]#./configure [root@nagios-server nrpe-2.13]#make all [root@nagios-server nrpe-2.13]#make install-plugin
七 、被监控客户端安装
说明:客户端只要安装nagios-plugins和NRPE就行了。客户端最好也像上面服务端那样更换一下yum源
1.安装前准备:
(1)关闭防火墙:
[root@nagios-client ~]# systemctl stop firewalld.service #停止firewall [root@nagios-client ~]# systemctl disable firewalld.service #禁止firewall的开机自启动
关闭selinux:
[root@nagios-client ~]# setenforce 0 [root@nagios-client ~]# sed -ri 's#^(SELINUX=).*#\1disabled#g' /etc/selinux/config
(3)调整字符集,如果不安装后面安装一些插件会有错误:
[root@nagios-client ~]# echo 'export LC_ALL=C' >>/etc/profile [root@nagios-client ~]# source /etc/profile
(4)时间同步,监控的时间同步很重要:
[root@nagios-client ~]# echo '# time sync' >>/var/spool/cron/root [root@nagios-client ~]# echo '*/10 * * * * /usr/sbin/ntpdate pool.ntp.org &>/dev/null' >>/var/spool/cron/root
(5)Nagios客户端需要安装一些依赖软件:
[root@nagios-client ~]#yum install -y gcc glibc glibc-common openssl-devel perl-devel
安装的软件说明:
gcc glibc glibc-common :这些是编译器所需,没有就无法编译源码,无法进行源码安装软件。
openssl-devel :这个是待会安装NRPE所需的依赖软件。
(6)创建所需用户:
[root@nagios-client ~]# useradd -m nagios -s /sbin/nologin
2.安装Nagios-plugins插件
刚才在Nagios服务端已经介绍了如何安装Nagios-plugins,这里就不重复细说了,此步骤跳过(跳过不是说不用装Nagios-plugins,先装Nagios-plugins再接着下面的步骤继续装NRPE)。
3.安装NRPE插件
(1)NRPE下载
[root@nagios-client ~]# cd /usr/local/src/ [root@nagios-client src]# wget http://prdownloads.sourceforge.net/sourceforge/nagios/nrpe-2.13.tar.gz
(2)NRPE解压编译安装
[root@nagios-client src]# tar zxf nrpe-2.13.tar.gz [root@nagios-client src]#cd nrpe-2.13 [root@nagios-client nrpe-2.13]# ./configure [root@nagios-client nrpe-2.13]#make all [root@nagios-client nrpe-2.13]#make install-plugin [root@nagios-client nrpe-2.13]#make install-daemon [root@nagios-client nrpe-2.13]#make install-daemon-config
说明:对比刚刚的Nagios服务端的NRPE安装过程,客户端安装NRPE时,多了两条命令(make install-daemon和make install-daemon-config),因为客户端需要运行NRPE daemon与服务端的check_nrpe插件交互,而服务端不需要运行NRPE,所以服务端安装NRPE时候不需要执行make install-daemon和make install-daemon-config。
八、客户端NRPE配置与启动(192.168.5.246)
1.允许被服务端监控
[root@nagios-client ~]# cd /usr/local/nagios/etc/ [root@nagios-client etc]# ls nrpe.cfg [root@nagios-client etc]# vim nrpe.cfg [root@nagios-client etc]# grep allowed_hosts nrpe.cfg allowed_hosts=127.0.0.1,::1,192.168.5.245 这里可以看到修改成功后的语句,注意标点符号,不要多也不要少。
说明:首先客户端要与服务端通信,那先得让客户端知道Nagios服务端的ip。打开nrpe.cfg 文件找到并把allowed_hosts=127.0.0.1,::1改为allowed_hosts=127.0.0.1,::1,192.168.5.245
这个添加的192.168.5.245是Nagios服务端的ip,修改完保存退出。
2.修改配置文件,告诉客户机的NRPE,该守护进程怎么去监控
[root@nagios-client etc]# vim nrpe.cfg 1
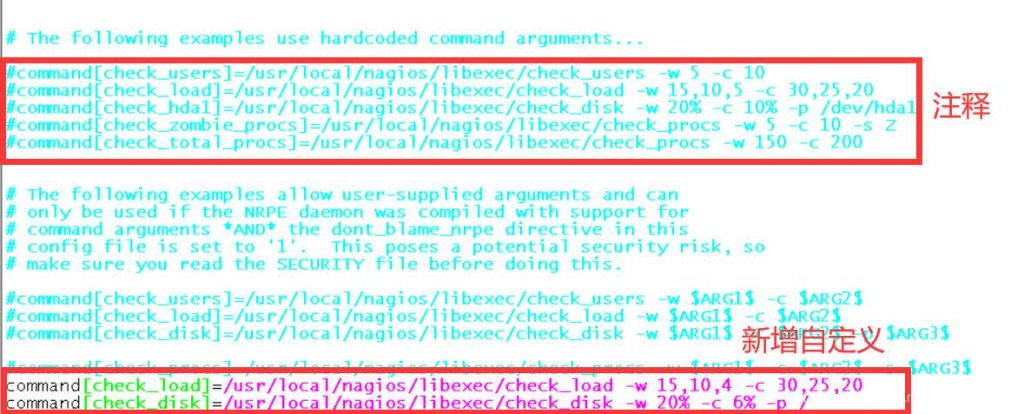
command[check_load]=/usr/local/nagios/libexec/check_load -w 15,10,4 -c 30,25,20 命令解释:当1分钟多于15个进程等待,5分钟多于10个,15分钟多于4个则为warning状态 当1分钟多于30个进程等待,5分钟多于25个,15分钟多于20个则为critical状态 [check_load]:相当于模块名 /usr/local/nagios/libexec/check_load:获取资源的命令 也就是说通过调用check_load就相当于执行/usr/local/nagios/libexec/check_load这个命令,下同。 command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 6% -p / 命令解释:-w 20% -c 6% -p /(根分区剩余空间为总大小的20%为warning状态,剩余6%为critical状态,-p后是根分区)
说明:再次打开nrpe.cfg 文件,打开后按shift+g,跳到文件内容最后面,可以发现上图中标记注释的语句,把它们都注释了吧!然后在文件内容最后添加两条命令,对应的是监控linux客户端的磁盘占用率和系统负载。
3.启动NRPE以及测试
[root@nagios-client etc]# /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d [root@nagios-client etc]# netstat -ptln | grep 5666 tcp 0 0 0.0.0.0:5666 0.0.0.0:* LISTEN 3182/nrpe [root@nagios-client etc]# /usr/local/nagios/libexec/check_nrpe -H localhost NRPE v2.13 [root@nagios-client etc]# /usr/local/nagios/libexec/check_nrpe -H localhost -c check_disk DISK OK - free space: / 13949 MB (80.19% inode=99%);| /=3444MB;13915;16002;0;17394 [root@nagios-client etc]# /usr/local/nagios/libexec/check_nrpe -H localhost -c check_load OK - load average: 0.00, 0.01, 0.05|load1=0.000;15.000;30.000;0; load5=0.010;10.000;25.000;0; load15=0.050;5.000;20.000;0;
说明:启动NRPE,启动成功后可以查看到nrpe占用的端口,然后测试服务端本地是否连通以及获取本机的磁盘占用率和系统负载,显示如上表示客户端的NRPE安装配置已完成。提示:重启nrpe 可以先用killall杀掉nrpe进程再启动即可
九、Nagios服务端配置与测试(192.168.5.245)
1.修改Nagios 主配置文件
[root@nagios-server ~]# cd /usr/local/nagios/etc/ [root@nagios-server etc]# ls cgi.cfg htpasswd.users nagios.cfg nrpe.cfg objects resource.cfg [root@nagios-server etc]# vim nagios.cfg
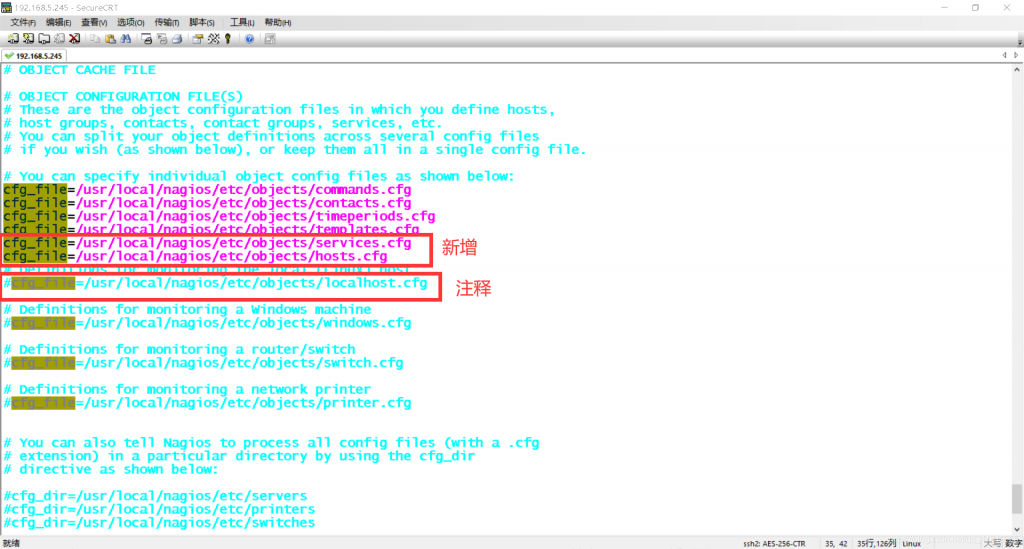
说明:注释掉的语句是:默认启动localhost.cfg监控本机的配置文件,这里我不需要监控本机,所以注释掉。新增的两个文件:hosts.cfg是即将新建的文件用来定义主机和主机组;services.cfg是即将新建的文件用来定义这些主机要监控的服务条目。
2.新建配置文件(hosts.cfg,services.cfg)
[root@nagios-server etc]# cd objects/ [root@nagios-server objects]# head -51 localhost.cfg >hosts.cfg [root@nagios-server objects]# touch services.cfg [root@nagios-server objects]# ll total 56 -rw-rw-r--. 1 nagios nagios 7832 Nov 15 23:52 commands.cfg -rw-rw-r--. 1 nagios nagios 2138 Nov 15 17:19 contacts.cfg -rw-r--r--. 1 nagios nagios 1843 Nov 16 15:15 hosts.cfg -rw-rw-r--. 1 nagios nagios 5379 Nov 15 17:19 localhost.cfg -rw-rw-r--. 1 nagios nagios 3070 Nov 15 17:19 printer.cfg -rw-r--r--. 1 nagios nagios 131 Nov 16 15:15 services.cfg -rw-rw-r--. 1 nagios nagios 3252 Nov 15 17:19 switch.cfg -rw-rw-r--. 1 nagios nagios 10595 Nov 15 17:19 templates.cfg -rw-rw-r--. 1 nagios nagios 3180 Nov 15 17:19 timeperiods.cfg -rw-rw-r--. 1 nagios nagios 3991 Nov 15 17:19 windows.cfg
说明:head -51 localhost.cfg >hosts.cfg :取 localhost.cfg中前51行的内容复制进hosts.cfg文件中。
执行ll查看文件详情,若看见services.cfg和hosts.cfg的用户和用户组不是nagios,需要执行如下命令(我这里显示是nagios,所以不用执行如下命令):
chown -R nagios.nagios services.cfg hosts.cfg
3.hosts.cfg和services.cfg文件的配置
(1)hosts.cfg配置
重要说明:复制以下配置信息的模板的时候,一定要记得把中文去掉,虽然中文前有#这个注释,但也要去掉中文,不然直接复制这些配置模板过去用会报错。
[root@nagios-server objects]# vim hosts.cfg
define host{
use linux-server #引用主机linux-server的属性信息,linux-server主机在templates.cfg文件中进行了定义。
host_name client #主机名
alias client #主机别名
address 192.168.5.246 #被监控的主机地址,这个地址可以是ip,也可以是域名。
}
define hostgroup{
hostgroup_name linux-servers #主机组名称,可以随意指定
alias Linux Servers #主机组别名
members client #主机组成员,“client”就是上面定义的主机。
}
说明:进入hosts.cfg后,将define host和define hostgroup改成上面的配置。
(2)services.cfg配置
[root@nagios-server objects]# vim services.cfg
define service{
use generic-service
host_name client #指定要监控哪个主机上的服务,“client”在hosts.cfg文件中进行了定义。
service_description Disk Partition #对监控服务内容的描述,以供维护人员参考。
check_command check_nrpe!check_disk #指定检查的命令。
}
define service{
use generic-service
host_name client
service_description Load
check_command check_nrpe!check_load
}
说明:进入services.cfg后,添加上面配置。本次实验只是监控客户端的磁盘占用率和系统负载,所以这里只配置了两个services,你们要想监控更多客户端的服务,可以直接添加services进来。
4.commands.cfg配置
(1)打开commands.cfg
[root@nagios-server objects]# vim commands.cfg
(2)进入后按shift+g,跳到文件内容的末尾,添加以下内容后,保存退出
#'check_nrpe' command definition
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
(3)测试命令可用性
[root@nagios-server etc]# /usr/local/nagios/libexec/check_nrpe -H 192.168.5.246 -c check_disk DISK OK - free space: / 13949 MB (80.19% inode=99%);| /=3444MB;13915;16002;0;17394
说明:# check_nrpe:Nagios服务端的命令,需要在commands.cfg文件中定义。#check_disk:调用客户端配置文件nrpe.cfg中[check_disk]标签后面的命令。可以查看到客户端的返回的磁盘占用情况,表明成功通过NRPE实现远程监控。如果获取不到被监控端的数据,第一:请检查客户端的NRPE是否正常运行,可通过netstat -ptln | grep 5666命令查看端口正常是否打开。第二:请检查服务端与客户端之间的防火墙是否关闭。第三:查看commands.cfg文件内新增的命令是否有错,第四:查看客户端的nrpe.cfg文件内的allowed_hosts=127.0.0.1语句后面是否添加了Nagios服务端的ip。
5.检查配置文件是否有错
(1)执行下面语句
[root@nagios-server etc]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg 1 Nagios Core 4.3.1 Copyright (c) 2009-present Nagios Core Development Team and Community Contributors Copyright (c) 1999-2009 Ethan Galstad Last Modified: 02-23-2017 License: GPL Website: https://www.nagios.org Reading configuration data... Read main config file okay... Read object config files okay... Running pre-flight check on configuration data... Checking objects... Checked 2 services. Checked 1 hosts. Checked 1 host groups. Checked 0 service groups. Checked 1 contacts. Checked 1 contact groups. Checked 25 commands. Checked 5 time periods. Checked 0 host escalations. Checked 0 service escalations. Checking for circular paths... Checked 1 hosts Checked 0 service dependencies Checked 0 host dependencies Checked 5 timeperiods Checking global event handlers... Checking obsessive compulsive processor commands... Checking misc settings... Total Warnings: 0 Total Errors: 0 Things look okay - No serious problems were detected during the pre-flight check
说明:看到Total Warnings: 0 Total Errors: 0,说明配置文件没有错误可以启动Nagios服务端进行测试了。若出现错误,按照提示的错误信息对配置文件逐一进行排查, Nagios服务端整个配置过程中的查错都是通过执行/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg语句反馈的结果来进行。
6.各个配置文件的关系图解
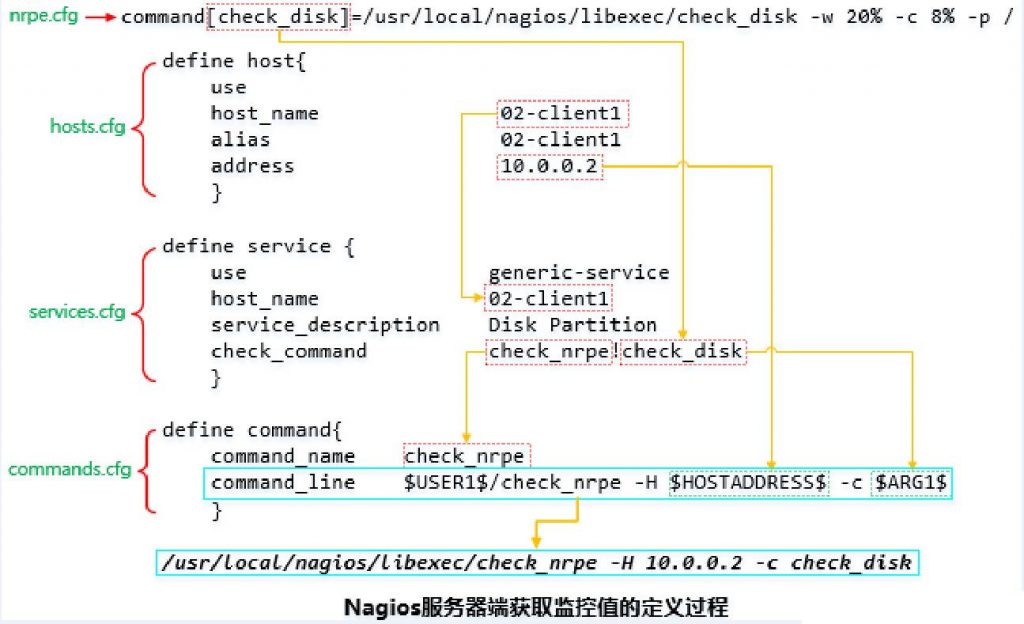
说明:仅供参考,结合本实验教程看图。
十、测试和排错思路
1.重启apache
[root@nagios-server etc]# systemctl restart httpd
[root@nagios-server etc]# systemctl status httpd
* httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2020-11-16 17:14:33 CST; 6s ago
Docs: man:httpd(8)
man:apachectl(8)
Process: 35865 ExecStop=/bin/kill -WINCH ${MAINPID} (code=exited, status=0/SUCCESS)
Main PID: 35869 (httpd)
Status: "Processing requests..."
CGroup: /system.slice/httpd.service
|-35869 /usr/sbin/httpd -DFOREGROUND
|-35872 /usr/sbin/httpd -DFOREGROUND
|-35873 /usr/sbin/httpd -DFOREGROUND
|-35874 /usr/sbin/httpd -DFOREGROUND
|-35875 /usr/sbin/httpd -DFOREGROUND
`-35876 /usr/sbin/httpd -DFOREGROUND
Nov 16 17:14:12 nagios-server systemd[1]: Starting The Apache HTTP Server...
Nov 16 17:14:23 nagios-server httpd[35869]: AH00558: httpd: Could not reliably determine the server's fully qualified...essage
Nov 16 17:14:33 nagios-server systemd[1]: Started The Apache HTTP Server.
Hint: Some lines were ellipsized, use -l to show in full.
2.重启Nagios
[root@nagios-server etc]# systemctl restart nagios [root@nagios-server etc]# systemctl status nagios * nagios.service - LSB: Starts and stops the Nagios monitoring server Loaded: loaded (/etc/rc.d/init.d/nagios; bad; vendor preset: disabled) Active: active (running) since Mon 2020-11-16 17:15:40 CST; 6s ago Docs: man:systemd-sysv-generator(8) Process: 35901 ExecStop=/etc/rc.d/init.d/nagios stop (code=exited, status=0/SUCCESS) Process: 35908 ExecStart=/etc/rc.d/init.d/nagios start (code=exited, status=0/SUCCESS) CGroup: /system.slice/nagios.service |-35931 /usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg |-35933 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh |-35934 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh |-35935 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh |-35936 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh `-35937 /usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg Nov 16 17:15:40 nagios-server nagios[35931]: nerd: Channel opathchecks registered successfully Nov 16 17:15:40 nagios-server nagios[35931]: nerd: Fully initialized and ready to rock! Nov 16 17:15:40 nagios-server nagios[35931]: wproc: Successfully registered manager as @wproc with query handler Nov 16 17:15:40 nagios-server systemd[1]: Started LSB: Starts and stops the Nagios monitoring server. Nov 16 17:15:40 nagios-server nagios[35908]: Starting nagios: done. Nov 16 17:15:40 nagios-server nagios[35931]: wproc: Registry request: name=Core Worker 35936;pid=35936 Nov 16 17:15:40 nagios-server nagios[35931]: wproc: Registry request: name=Core Worker 35933;pid=35933 Nov 16 17:15:40 nagios-server nagios[35931]: wproc: Registry request: name=Core Worker 35934;pid=35934 Nov 16 17:15:40 nagios-server nagios[35931]: wproc: Registry request: name=Core Worker 35935;pid=35935 Nov 16 17:15:40 nagios-server nagios[35931]: Successfully launched command file worker with pid 35937
3.打开浏览器测试
(1)输入:Nagios服务端ip/nagios,我这里是192.168.5.245/nagios,用户:wang,密码123456。
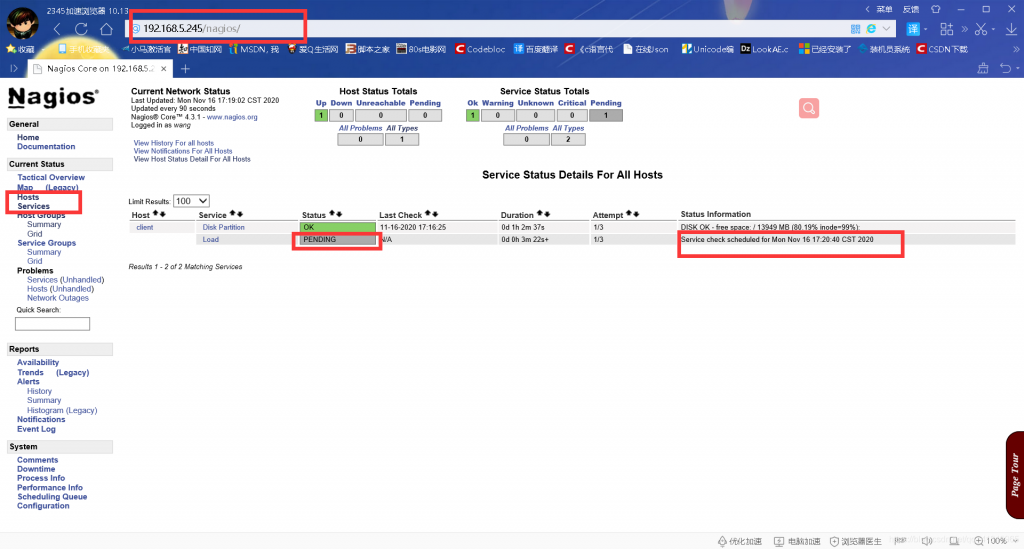 说明:进去后点击Hosts查看配置的被监控的主机是否在线,然后点击Services查看配置的服务是否正常,如果出现上图中Load这个服务的状态是PENDING(等待中),请耐心等到Status Infomation中显示的时间,一般到了那个时间所有Services的状态都会显示OK,到此Nagios的安装和配置也即将告一段落。
说明:进去后点击Hosts查看配置的被监控的主机是否在线,然后点击Services查看配置的服务是否正常,如果出现上图中Load这个服务的状态是PENDING(等待中),请耐心等到Status Infomation中显示的时间,一般到了那个时间所有Services的状态都会显示OK,到此Nagios的安装和配置也即将告一段落。
4.排错的思路
(1) 状态为CRITICAL
这种问题就是连接失败,可能是服务没起,也可能是防火墙没关。我们可以现在本地执行:
/usr/local/nagios/libexec/check_nrpe -H 客户端ip -c check_disk
(3) 命令行执行能够获取数值,但是web界面去获取不到。
define service {
use generic-service
host_name 02-client1,01-nagios
service_description Disk Partition
check_command check_nrpe!check_disk # 肯定是这个参数定义错了
}
(4) Web界面的Services的Status Information中出现Unable to read output
出现这种问题的原因就是获取值的插件没有执行权限,或者是这插件就是有问题的,总之就是插件的错。
[root@nagios-server etc]# chmod +x 插件名 # 执行该命令,如果还是不行,那就是插件本身的问题了
(5)总结,当web界面显示出现问题时:
Nagios自身和配置文件有问题
在服务器端执行:
/usr/local/nagios/libexec/check_nrpe -H 被监控主机地址-c 获取值的命令
在客户端本地执行:
/usr/local/nagios/libexec/check_nrpe -H 127.0.0.1 -c获取值的命令
执行nrpe.cfg配置文件中的获取值的命令:
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 8% -p / # 执行该命令
检查客户端系统自带的防火强,是否stop了5666端口;客户端中的nrpe添加完命令后,有没有真正重启;客户端中的nrpe.cfg配置文件中的allow_hosts这行的ip千万不要加错了。
十一、Nagios服务端配置文件详解
1.templates.cfg文件
nagios主要用于监控主机资源以及服务,在nagios配置中称为对象,为了不必重复定义一些监控对象,Nagios引入了一个模板配置文件,将一些共性的属性定义成模板,以便于多次引用。这就是templates.cfg的作用。
define contact{
name generic-contact ; 联系人名称
service_notification_period 24x7 ; 当服务出现异常时,发送通知的时间段,这个时间段"24x7"在timeperiods.cfg文件中定义
host_notification_period 24x7 ; 当主机出现异常时,发送通知的时间段,这个时间段"24x7"在timeperiods.cfg文件中定义
service_notification_options w,u,c,r ; 这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态,u即unknown,表示不明状态;
; c即criticle,表示紧急状态,r即recover,表示恢复状态;
; 也就是在服务出现警告状态、未知状态、紧急状态和重新恢复状态时都发送通知给使用者。
host_notification_options d,u,r ; 定义主机在什么状态下需要发送通知给使用者,d即down,表示宕机状态;
; u即unreachable,表示不可到达状态,r即recovery,表示重新恢复状态。
service_notification_commands notify-service-by-email ; 服务故障时,发送通知的方式,可以是邮件和短信,这里发送的方式是邮件;
; 其中“notify-service-by-email”在commands.cfg文件中定义。
host_notification_commands notify-host-by-email ; 主机故障时,发送通知的方式,可以是邮件和短信,这里发送的方式是邮件;
; 其中“notify-host-by-email”在commands.cfg文件中定义。
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL CONTACT, JUST A TEMPLATE!
}
define host{
name generic-host ; 主机名称,这里的主机名,并不是直接对应到真正机器的主机名;
; 乃是对应到在主机配置文件里所设定的主机名。
notifications_enabled 1 ; Host notifications are enabled
event_handler_enabled 1 ; Host event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
failure_prediction_enabled 1 ; Failure prediction is enabled
process_perf_data 1 ; 其值可以为0或1,其作用为是否启用Nagios的数据输出功能;
; 如果将此项赋值为1,那么Nagios就会将收集的数据写入某个文件中,以备提取。
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
notification_period 24x7 ; 指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}
define host{
name linux-server ; 主机名称
use generic-host ; use表示引用,也就是将主机generic-host的所有属性引用到linux-server中来;
; 在nagios配置中,很多情况下会用到引用。
check_period 24x7 ; 这里的check_period告诉nagios检查主机的时间段
check_interval 5 ; nagios对主机的检查时间间隔,这里是5分钟。
retry_interval 1 ; 重试检查时间间隔,单位是分钟。
max_check_attempts 10 ; nagios对主机的最大检查次数,也就是nagios在检查发现某主机异常时,并不马上判断为异常状况;
; 而是多试几次,因为有可能只是一时网络太拥挤,或是一些其他原因,让主机受到了一点影响;
; 这里的10就是最多试10次的意思。
check_command check-host-alive ; 指定检查主机状态的命令,其中“check-host-alive”在commands.cfg文件中定义。
notification_period 24x7 ; 主机故障时,发送通知的时间范围,其中“workhours”在timeperiods.cfg中进行了定义;
; 下面会陆续讲到。
notification_interval 10 ; 在主机出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟;
; 如果你觉得,所有的事件只需要一次通知就够了,可以把这里的选项设为0
notification_options d,u,r ; 定义主机在什么状态下可以发送通知给使用者,d即down,表示宕机状态;
; u即unreachable,表示不可到达状态;
; r即recovery,表示重新恢复状态。
contact_groups ts ; 指定联系人组,这个“admins”在contacts.cfg文件中定义。
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}
define host{
name windows-server ; The name of this host template
use generic-host ; Inherit default values from the generic-host template
check_period 24x7 ; By default, Windows servers are monitored round the clock
check_interval 5 ; Actively check the server every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each server 10 times (max)
check_command check-host-alive ; Default command to check if servers are "alive"
notification_period 24x7 ; Send notification out at any time - day or night
notification_interval 10 ; Resend notifications every 30 minutes
notification_options d,r ; Only send notifications for specific host states
contact_groups ts ; Notifications get sent to the admins by default
hostgroups windows-servers ; Host groups that Windows servers should be a member of
register 0 ; DONT REGISTER THIS - ITS JUST A TEMPLATE
}
define service{
name generic-service ; 定义一个服务名称
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized;
; (disabling this can lead to major performance problems)
obsess_over_service 1 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
failure_prediction_enabled 1 ; Failure prediction is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
is_volatile 0 ; The service is not volatile
check_period 24x7 ; 这里的check_period告诉nagios检查服务的时间段。
max_check_attempts 3 ; nagios对服务的最大检查次数。
normal_check_interval 5 ; 此选项是用来设置服务检查时间间隔,也就是说,nagios这一次检查和下一次检查之间所隔的时间;
; 这里是5分钟。
retry_check_interval 2 ; 重试检查时间间隔,单位是分钟。
contact_groups ts ; 指定联系人组
notification_options w,u,c,r ; 这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态;
; u即unknown,表示不明状态;
; c即criticle,表示紧急状态,r即recover,表示恢复状态;
; 也就是在服务出现警告状态、未知状态、紧急状态和重新恢复后都发送通知给使用者。
notification_interval 10 ; Re-notify about service problems every hour
notification_period 24x7 ; 指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL SERVICE, JUST A TEMPLATE!
}
define service{
name local-service ; The name of this service template
use generic-service ; Inherit default values from the generic-service definition
max_check_attempts 4 ; Re-check the service up to 4 times in order to determine its final (hard) state
normal_check_interval 5 ; Check the service every 5 minutes under normal conditions
retry_check_interval 1 ; Re-check the service every minute until a hard state can be determined
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL SERVICE, JUST A TEMPLATE!
}
2.resource.cfg文件
resource.cfg是nagios的变量定义文件,文件内容只有一行,其中,变量U S E R 1 USER1USER1指定了安装nagios插件的路径,如果把插件安装在了其它路径,只需在这里进行修改即可。需要注意的是,变量必须先定义,然后才能在其它配置文件中进行引用。
$USER1$=/usr/local/nagios/libexec
3.commands.cfg文件
此文件默认是存在的,无需修改即可使用,当然如果有新的命令需要加入时,在此文件进行添加即可。
#notify-host-by-email命令的定义
define command{
command_name notify-host-by-email #命令名称,即定义了一个主机异常时发送邮件的命令。
command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState: $HOSTSTATE$\nAddress: $HOSTADDRESS$\nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$\n" | /bin/mail -s "** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **" $CONTACTEMAIL$ #命令具体的执行方式。
}
#notify-service-by-email命令的定义
define command{
command_name notify-service-by-email #命令名称,即定义了一个服务异常时发送邮件的命令
command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$\n" | /bin/mail -s "** $NOTIFICATIONTYPE$ Service Alert: $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **" $CONTACTEMAIL$
}
#check-host-alive命令的定义
define command{
command_name check-host-alive #命令名称,用来检测主机状态。
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 5
# 这里的变量$USER1$在resource.cfg文件中进行定义,即$USER1$=/usr/local/nagios/libexec;
# 那么check_ping的完整路径为/usr/local/nagios/libexec/check_ping;
# “-w 3000.0,80%”中“-w”说明后面的一对值对应的是“WARNING”状态,“80%”是其临界值。
# “-c 5000.0,100%”中“-c”说明后面的一对值对应的是“CRITICAL”,“100%”是其临界值。
# “-p 1”说明每次探测发送一个包。
}
define command{
command_name check_local_disk
command_line $USER1$/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$ #$ARG1$是指在调用这个命令的时候,命令后面的第一个参数。
}
define command{
command_name check_local_load
command_line $USER1$/check_load -w $ARG1$ -c $ARG2$
}
define command{
command_name check_local_procs
command_line $USER1$/check_procs -w $ARG1$ -c $ARG2$ -s $ARG3$
}
define command{
command_name check_local_users
command_line $USER1$/check_users -w $ARG1$ -c $ARG2$
}
define command{
command_name check_local_swap
command_line $USER1$/check_swap -w $ARG1$ -c $ARG2$
}
define command{
command_name check_ftp
command_line $USER1$/check_ftp -H $HOSTADDRESS$ $ARG1$
}
define command{
command_name check_http
command_line $USER1$/check_http -I $HOSTADDRESS$ $ARG1$
}
define command{
command_name check_ssh
command_line $USER1$/check_ssh $ARG1$ $HOSTADDRESS$
}
define command{
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}
define command{
command_name check_nt
command_line $USER1$/check_nt -H $HOSTADDRESS$ -p 12489 -v $ARG1$ $ARG2$
}
4.hosts.cfg文件
此文件默认不存在,需要手动创建,hosts.cfg主要用来指定被监控的主机地址以及相关属性信息,根据实验目标配置如下:
define host{
use linux-server #引用主机linux-server的属性信息,linux-server主机在templates.cfg文件中进行了定义。
host_name Nagios-Linux #主机名
alias Nagios-Linux #主机别名
address 192.168.1.111 #被监控的主机地址,这个地址可以是ip,也可以是域名。
}
#定义一个主机组
define hostgroup{
hostgroup_name bsmart-servers #主机组名称,可以随意指定。
alias bsmart servers #主机组别名
members Nagios-Linux #主机组成员,其中“Nagios-Linux”就是上面定义的主机。
}
注意:在/usr/local/nagios/etc/objects 下默认有localhost.cfg 和windows.cfg 这两个配置文件,localhost.cfg 文件是定义监控主机本身的,windows.cfg 文件是定义windows 主机的,其中包括了对host 和相关services 的定义。所以在本次实验中,将直接在localhost.cfg 中定义监控主机(Nagios-Server),在windows.cfg中定义windows 主机(Nagios-Windows)。根据自己的需要修改其中的相关配置,详细如下:
5.localhost.cfg
define host{
use linux-server ; Name of host template to use
; This host definition will inherit all variables that are defined
; in (or inherited by) the linux-server host template definition.
host_name Nagios-Server
alias Nagios-Server
address 127.0.0.1
}
define hostgroup{
hostgroup_name linux-servers ; The name of the hostgroup
alias Linux Servers ; Long name of the group
members Nagios-Server ; Comma separated list of hosts that belong to this group
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description Root Partition
check_command check_local_disk!20%!10%!/
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description Current Users
check_command check_local_users!20!50
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description Total Processes
check_command check_local_procs!250!400!RSZDT
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description Current Load
check_command check_local_load!5.0,4.0,3.0!10.0,6.0,4.0
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description Swap Usage
check_command check_local_swap!20!10
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description SSH
check_command check_ssh
notifications_enabled 0
}
define service{
use local-service ; Name of service template to use
host_name Nagios-Server
service_description HTTP
check_command check_http
notifications_enabled 0
}
6.windows.cfg
define host{
use windows-server ; Inherit default values from a template
host_name Nagios-Windows ; The name we're giving to this host
alias My Windows Server ; A longer name associated with the host
address 192.168.1.113 ; IP address of the host
}
define hostgroup{
hostgroup_name windows-servers ; The name of the hostgroup
alias Windows Servers ; Long name of the group
}
define service{
use generic-service
host_name Nagios-Windows
service_description NSClient++ Version
check_command check_nt!CLIENTVERSION
}
define service{
use generic-service
host_name Nagios-Windows
service_description Uptime
check_command check_nt!UPTIME
}
define service{
use generic-service
host_name Nagios-Windows
service_description CPU Load
check_command check_nt!CPULOAD!-l 5,80,90
}
define service{
use generic-service
host_name Nagios-Windows
service_description Memory Usage
check_command check_nt!MEMUSE!-w 80 -c 90
}
define service{
use generic-service
host_name Nagios-Windows
service_description C:\ Drive Space
check_command check_nt!USEDDISKSPACE!-l c -w 80 -c 90
}
define service{
use generic-service
host_name Nagios-Windows
service_description W3SVC
check_command check_nt!SERVICESTATE!-d SHOWALL -l W3SVC
}
define service{
use generic-service
host_name Nagios-Windows
service_description Explorer
check_command check_nt!PROCSTATE!-d SHOWALL -l Explorer.exe
}
7.services.cfg文件
此文件默认也不存在,需要手动创建,services.cfg文件主要用于定义监控的服务和主机资源,例如监控http服务、ftp服务、主机磁盘空间、主机系统负载等等。Nagios-Server 和Nagios-Windows 相关服务已在相应的配置文件中定义,所以这里只需要定义Nagios-Linux 相关服务即可,这里只定义一个检测是否存活的服务来验证配置文件的正确性,其他服务的定义将在后面讲到。
define service{
use local-service #引用local-service服务的属性值,local-service在templates.cfg文件中进行了定义。
host_name Nagios-Linux #指定要监控哪个主机上的服务,“Nagios-Server”在hosts.cfg文件中进行了定义。
service_description check-host-alive #对监控服务内容的描述,以供维护人员参考。
check_command check-host-alive #指定检查的命令。
}
8.contacts.cfg文件
contacts.cfg是一个定义联系人和联系人组的配置文件,当监控的主机或者服务出现故障,nagios会通过指定的通知方式(邮件或者短信)将信息发给这里指定的联系人或者使用者。
#下面是定义一个名为24x7的时间段,即监控所有时间段
define timeperiod{
timeperiod_name 24x7 #时间段的名称,这个地方不要有空格
alias 24 Hours A Day, 7 Days A Week
sunday 00:00-24:00
monday 00:00-24:00
tuesday 00:00-24:00
wednesday 00:00-24:00
thursday 00:00-24:00
friday 00:00-24:00
saturday 00:00-24:00
}
#下面是定义一个名为workhours的时间段,即工作时间段。
define timeperiod{
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}
10.cgi.cfg文件
此文件用来控制相关cgi脚本,如果想在nagios的web监控界面执行cgi脚本,例如重启nagios进程、关闭nagios通知、停止nagios主机检测等,这时就需要配置cgi.cfg文件了。
由于nagios的web监控界面验证用户为david,所以只需在cgi.cfg文件中添加此用户(添加的参考用户为david)的执行权限就可以了,需要修改的配置信息如下:
default_user_name=david authorized_for_system_information=nagiosadmin,david authorized_for_configuration_information=nagiosadmin,david authorized_for_system_commands=david authorized_for_all_services=nagiosadmin,david authorized_for_all_hosts=nagiosadmin,david authorized_for_all_service_commands=nagiosadmin,david authorized_for_all_host_commands=nagiosadmin,david
11.nagios.cfg文件
nagios.cfg默认的路径为/usr/local/nagios/etc/nagios.cfg,是nagios的核心配置文件,所有的对象配置文件都必须在这个文件中进行定义才能发挥其作用,这里只需将对象配置文件在Nagios.cfg文件中进行引用即可。
log_file=/usr/local/nagios/var/nagios.log # 定义nagios日志文件的路径 cfg_file=/usr/local/nagios/etc/objects/commands.cfg # “cfg_file”变量用来引用对象配置文件,如果有更多的对象配置文件,在这里依次添加即可。 cfg_file=/usr/local/nagios/etc/objects/contacts.cfg cfg_file=/usr/local/nagios/etc/objects/hosts.cfg cfg_file=/usr/local/nagios/etc/objects/services.cfg cfg_file=/usr/local/nagios/etc/objects/timeperiods.cfg cfg_file=/usr/local/nagios/etc/objects/templates.cfg cfg_file=/usr/local/nagios/etc/objects/localhost.cfg # 本机配置文件 cfg_file=/usr/local/nagios/etc/objects/windows.cfg # windows 主机配置文件 object_cache_file=/usr/local/nagios/var/objects.cache # 该变量用于指定一个“所有对象配置文件”的副本文件,或者叫对象缓冲文件 precached_object_file=/usr/local/nagios/var/objects.precache resource_file=/usr/local/nagios/etc/resource.cfg # 该变量用于指定nagios资源文件的路径,可以在nagios.cfg中定义多个资源文件。 status_file=/usr/local/nagios/var/status.dat # 该变量用于定义一个状态文件,此文件用于保存nagios的当前状态、注释和宕机信息等。 status_update_interval=10 # 该变量用于定义状态文件(即status.dat)的更新时间间隔,单位是秒,最小更新间隔是1秒。 nagios_user=nagios # 该变量指定了Nagios进程使用哪个用户运行。 nagios_group=nagios # 该变量用于指定Nagios使用哪个用户组运行。 check_external_commands=1 # 该变量用于设置是否允许nagios在web监控界面运行cgi命令; # 也就是是否允许nagios在web界面下执行重启nagios、停止主机/服务检查等操作; # “1”为运行,“0”为不允许。 command_check_interval=10s # 该变量用于设置nagios对外部命令检测的时间间隔,如果指定了一个数字加一个"s"(如10s); # 那么外部检测命令的间隔是这个数值以秒为单位的时间间隔; # 如果没有用"s",那么外部检测命令的间隔是以这个数值的“时间单位”的时间间隔。 interval_length=60 # 该变量指定了nagios的时间单位,默认值是60秒,也就是1分钟; # 即在nagios配置中所有的时间单位都是分钟。
十二、报警
1.邮件报警
这是必须会的,生产环境中应尽量使用自己公司的信箱作为报警信箱,或者建立一个邮箱组(邮件列表)。尽量不用非公司信箱作为报警信箱,如126、qq等,因为这些信箱是免费的,对报警的频率等会有限制,很有可能会拒收或当成垃圾邮件,导致报警延时或无法收到。适用于重要且不紧急的业务报警。
2.邮件转短信报警
收到邮件会短信提醒,就相当于短信报警的功能。这是由邮箱提供商提供的一个功能,但报警内容长度有限制。
3.http短信网关
有专门的公司提供直接发送信息到手机的短信网关,常用的报警就是一个URL地址携带信息,收短信费。这是推荐的报警方式。
4.购买短信猫
类似于手机终端一样的客户端硬件设备,早期报警选用的方式,收短信费。
5.电话语音报警
先将报警语音录下来,报警时直接打电话到报警负责人,播放报警语音;也可以用语音识别软件,将文字识别为语音。
6.QQ/微信
模拟QQ,微信发信息的功能,QQ不太稳定;微信实际上就是将微信和邮箱绑定,当邮箱收到邮件时,微信会提醒
在生产环境中,一般会根据业务的紧急程度不同,多个报警策略结合使用。对于不需要紧急处理的业务一般选择邮件报警,如内存、磁盘空间的剩余率;对于重要且紧急的业务,会使用邮件加上短信同时报警。使用邮件报警便于记录故障详细信息,短息报警时及时提醒,优点是及时。短信报警的缺点是报警内容有限,所以在工作中如果接到严重报警时,我们紧急处理之前也会开启邮件系统先查看邮件细节。
推荐使用的短信报警方式,原因:
(1) 简单、易用;
(2) 稳定、可靠;
(3) 收费合理,类似个人手机一样,收取发送费用。
说明:至于怎么实现监控信息及时的通过邮箱或其他途径反馈给运维人员,请自行百度学习。具体实现步骤省略。
版权声明:本文为CSDN博主「Eye to eye」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41819965/article/details/109702039
您可以选择一种方式赞助本站
支付宝扫一扫赞助
微信钱包扫描赞助
赏