
Hadoop是一个用Java编写的Apache开源框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。Hadoop框架工作的应用程序在跨计算机集群提供分布式存储和计算的环境中工作。Hadoop旨在从单个服务器扩展到数千个机器,每个都提供本地计算和存储。
Hadoop框架包括以下四个模块:
-
*Hadoop Common:* 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
-
Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
-
*Hadoop Distributed File System (HDFS™):* 分布式文件系统,提供对应用程序数据的高吞吐量访问。
-
Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
sudo vi /etc/hostname #修改主机名(如,删掉原有内容,命名为 hadoop) ping hadoop #ping 通证明成功
sudo apt install openjdk-8-jdk-headless
配置JAVA环境变量,在当前用户根目录下的.profile文件最下面加入以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source
source .profile rogn@ubuntu:~$ java -version openjdk version "1.8.0_252" OpenJDK Runtime Environment (build 1.8.0_252-8u252-b09-1~16.04-b09) OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode)
3. 下载hadoop 3.2.1
wget http://mirrors.ustc.edu.cn/apache/hadoop/common/stable/hadoop-3.2.1.tar.gz tar -zxvf hadoop-3.2.1.tar.gz
再次修改 ~/.bashrc,在末尾添加:
export HADOOP_HOME=/home/rogn/Downloads/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
source ~/.bashrc
安装openssh-server( 通常Linux系统会默认安装openssh的客户端软件openssh-client),所以需要自己安装一下服务端。
sudo apt-get install openssh-server
输入 cd .ssh目录下,如果没有.ssh文件 输入 ssh localhost生成。
cd ~/.ssh/
生成秘钥
ssh-keygen -t rsa
将Master中生成的密钥加入授权(authorized_keys)
cat id_rsa.pub >> authorized_keys # 加入授权 chmod 600 authorized_keys # 修改文件权限,如果不修改文件权限,那么其它用户就能查看该授权
完成后,直接键入“ssh localhost”,能无密码登录即可,
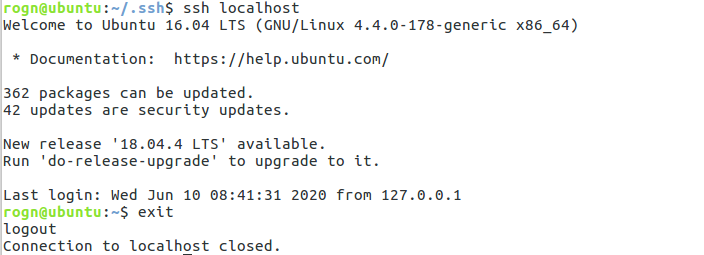
键入“exit”退出,到此SSH无密码登录配置就成功了。
$./bin/hdfs namenode -format
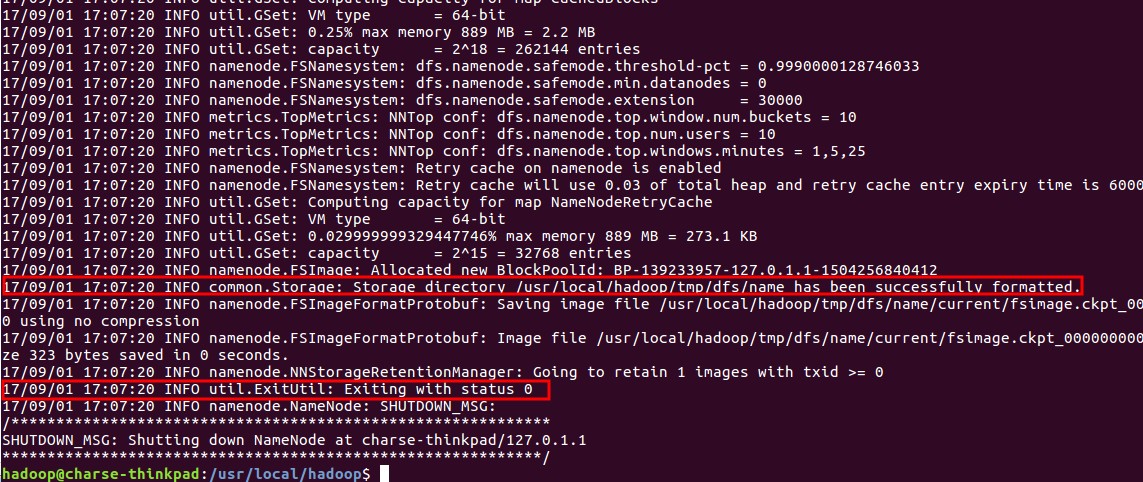
注意:不能进行多次格式化操作
启动hdfs
sbin/start-dfs.sh
启动YARN集群
sbin/start-yarn.sh
可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”

建立测试文件:
# vim test.txt
然后输入如下数据
hello hadoop hello World Hello Java Hey man i am a programmer
将测试文件放到测试目录中:
# hdfs dfs -mkdir hdfs:///wordlab # hdfs dfs -mkdir hdfs:///wordlab/input # hdfs dfs -put ./test.txt hdfs:///wordlab/input
执行hadoop自带的wordcount程序:
hadoop jar /home/rogn/Downloads/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount hdfs:///wordlab/input hdfs:///wordlab/output
查看词频统计的结果
# hdfs dfs -cat hdfs:///wordlab/output/part-r-00000
删除文件夹:
hdfs dfs -rm -r hdfs:///wordlab/output/
列出文件:
hdfs dfs -ls hdfs:///wordlab
您可以选择一种方式赞助本站
支付宝扫一扫赞助
微信钱包扫描赞助
赏